

Brooklin是一种分布式的数据流服务,可以提供近乎实时和大规模的数据流服务。自2016年以来,该服务已经在LinkedIn上运行,每天为数千条数据流和超过2万亿条消息传输提供支持。近日,LinkedIn宣布开源Brooklin。
为什么开发Brooklin?
LinkedIn开发Brooklin是为了满足他们日益增长的系统需求,该系统能够根据数据量和系统方差进行伸缩。同时,为了满足对可伸缩、低延迟数据处理管道不断增长的需求,LinkedIn的数据基础设施一直在不断的发展。尽管具有挑战性,但是如何以高速率可靠的移动大量数据并不是唯一必须解决的问题。支持快速增长的各种数据存储和消息传递系统已被证明是与任何可行解决方案同样重要的措施。
什么是Brooklin?
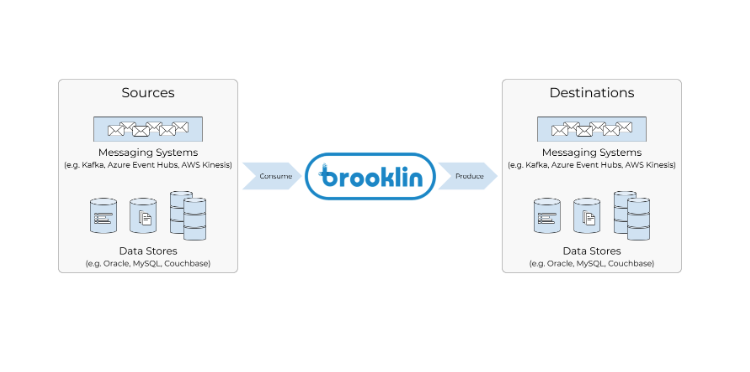
Brooklin是一个分布式系统,用于跨多个不同的数据存储和消息传递系统传输数据,具有很高的可靠性。它公开了一组抽象,通过编写新的Brooklin消费者和生产者,来扩展它的功能,支持在新系统和新系统之间消费和生产数据。在LinkedIn,Brooklin被用来作为跨不同存储系统(如Espresso和Oracle)和消息系统(如Kafka、Azure Event hub和AWS Kinesis)传输数据的主要解决方案。
Brooklin支持从各种数据源到各种目的地(消息传递系统和数据存储)的流数据流
应用场景
Brooklin有两大类应用场景:流桥和变更数据捕获。
流桥
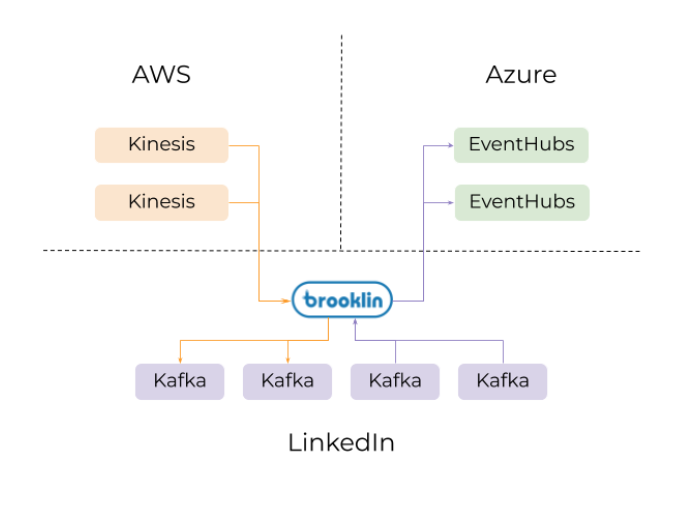
数据可以跨不同的环境(公共云和公司数据中心)、地理位置或不同的部署组传播。通常,由于访问机制、序列化格式、遵从性或安全需求的不同,每个环境都会增加额外的复杂性。Brooklin可被用作跨此类环境传输数据的桥梁。例如,Brooklin可以在不同的云服务(如AWS Kinesis和Microsoft Azure)之间、数据中心内的不同集群之间甚至跨数据中心移动数据。
举个例子,一个Brooklin集群被用作一个流桥,将数据从AWS Kinesis移动到Kafka,并将数据从Kafka移动到Azure事件中心。
因为Brooklin是一个专门用于跨各种环境流数据的服务,所以所有的复杂性都可以在一个服务中进行管理,从而允许应用程序开发人员专注于处理数据,而不是移动数据。此外,这个集中的、受管理的和可扩展的框架使组织能够执行策略并促进数据治理。例如,可以将Brooklin配置为强制公司范围内的策略,比如要求流入的任何数据必须是JSON格式的,或者流出的任何数据必须加密。
Kafka镜像
在Brooklin出来之前,LinkedIn是使用Kafka MirrorMaker (KMM)将Kafka数据从一个集群镜像到另一个集群,但是在使用过程中遇到了伸缩问题。由于Brooklin被设计为流数据的通用桥梁,用户能够轻松地添加对移动大量Kafka数据的支持。这使得LinkedIn可以离开KMM,并将Kafka镜像解决方案整合到Brooklin。
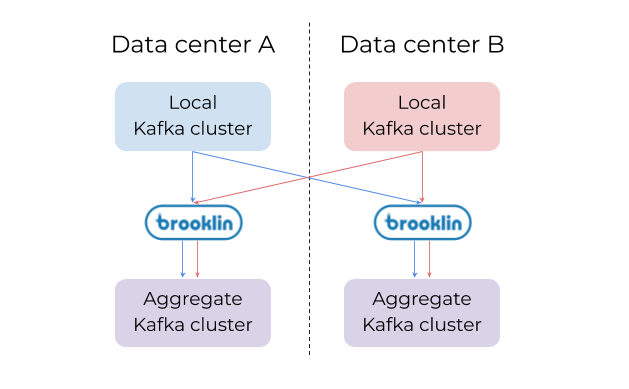
Brooklin作为LinkedIn的流媒体桥梁的最大用例之一是在集群和数据中心之间镜像Kafka数据。Kafka在LinkedIn中被大量使用来存储所有类型的数据,比如日志、跟踪、度量等等。用户使用Brooklin跨数据中心聚合这些数据,以便在集中的地方轻松访问。同时还使用Brooklin在LinkedIn和Azure之间移动大量Kafka数据。
例如:Brooklin用于跨两个数据中心聚合Kafka数据,使得从任何数据中心访问整个数据集变得很容易。每个数据中心中的一个Brooklin集群可以处理多个源和目标。
Brooklin镜像用于Kafka数据的解决方案已经通过大规模测试,因为它已经完全取代了LinkedIn的Kafka镜像器,每天镜像数万亿条信息。该解决方案解决了使用Kafka MirrorMaker的主要难点,在稳定性和可操作性上得到了优化。通过在Brooklin之上构建这个Kafka镜像的解决方案,就能够从它的一些关键功能中获益,下面将会详细讨论这些功能。
多租户
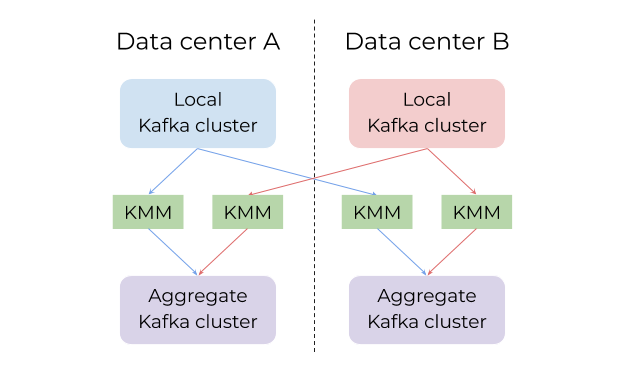
在Kafka MirrorMaker部署模型中,每个集群只能配置为在两个Kafka集群之间镜像数据。因此,KMM用户通常需要操作数十个甚至数百个单独的KMM集群,每个集群对应一个管道。事实证明,这是非常难以管理的。然而,由于Brooklin被设计成同时处理多个独立的数据管道,因此我们能够使用一个Brooklin集群来保持多个Kafka集群的同步,从而降低了维护数百个KMM集群的可操作性和复杂性。
Kafka MirrorMaker (KMM)用于跨两个数据中心聚合Kafka数据的一个假设示例。与Brooklin镜像拓扑相比,需要更多的KMM集群(每个源/目标对一个KMM集群)。
动态供应和管理
使用Brooklin,创建新的数据渠道(也称为datastreams)和修改现有渠道可以很容易地通过对REST端点的HTTP调用完成。对于Kafka镜像用例,这个端点使创建新的镜像渠道或修改现有渠道的镜像白名单变得非常容易,而不需要更改和部署静态配置。
尽管镜像渠道可以在同一个集群中共存,但Brooklin公开了单独控制和配置每个渠道的能力。例如,可以编辑渠道的镜像白名单或向渠道添加更多资源而不影响其他任何资源。此外,Brooklin允许按需暂停和恢复单个渠道,这在临时操作或修改渠道时非常有用。对于Kafka镜像用例,Brooklin支持暂停或恢复整个渠道、白名单中的单个主题,甚至单个主题分区。
诊断
Brooklin还公开了一个诊断REST端点,该端点支持按需查询数据流的状态。这个API使查询管道的内部状态变得很容易,包括任何单独的主题分区延迟或错误。由于诊断端点合并了来自整个Brooklin集群的所有结果,这对于快速诊断特定分区的问题非常有用,而不需要扫描日志文件。
特殊功能
由于它是作为Kafka镜像器的替代品,Brooklin的Kafka镜像解决方案经过了稳定性和可操作性的优化。因此,我们介绍了Kafka镜像特有的一些改进。
最重要的是,LinkedIn努力实现更好的故障隔离,这样镜像特定分区或主题的错误不会影响整个管道或集群,就像对KMM所做的那样。Brooklin能够在分区级别检测错误,并自动暂停对这些问题分区的镜像。这些自动暂停的分区可以在经过一段可配置的时间后自动恢复,这消除了手动干预的需要,对于临时错误尤其有用。同时,其他分区和管道的处理不受影响。
为了改进镜像延迟和吞吐量,Brooklin Kafka镜像还可以在非刷新生产模式下运行,在这种模式下,Kafka的消费进度可以在分区级别上跟踪。对每个分区执行检查点,而不是在管道级别。这使得Brooklin避免了昂贵的Kafka生成器刷新调用,这是同步阻塞调用,通常会使整个管道停顿几分钟。
通过将LinkedIn的Kafka MirrorMaker部署迁移到Brooklin,我们能够将镜像集群的数量从数百个减少到大约12个。利用Brooklin实现卡夫卡镜像的目的还能够不断地添加特性和改进,来更快的进行迭代。
变更数据捕获(CDC)
Brooklin的第二个主要用例类别是变更数据捕获。在这些情况下,目标是以低延迟更改流的形式流媒体数据库更新。例如,LinkedIn的大部分真实数据来源(如工作、联系和个人资料信息)都位于不同的数据库中。几个应用程序都有兴趣知道何时发布新工作、建立新的专业连接或更新成员的个人资料。Brooklin不需要让这些感兴趣的应用程序对在线数据库进行昂贵的查询来检测这些更改,而是可以几乎实时地传输这些数据库更新。使用Brooklin生成变更数据捕获事件的最大优势之一是应用程序和在线商店之间更好的资源隔离。应用程序可以独立于数据库进行伸缩,从而避免了关闭数据库的风险。使用Brooklin,我们在LinkedIn为Oracle、Espresso和MySQL构建了变更数据捕获解决方案;此外,Brooklin的可扩展模型便于编写新的连接器来为任何数据库源添加CDC支持。
更改数据捕获可用于捕获对在线数据源进行的更新,并将其传播到许多应用程序进行近线处理。一个示例用例就是一个通知服务/应用程序,它侦听任何概要文件更新,以便能够向每个相关用户显示通知。
Bootstrap支持
有时,应用程序在使用增量更新之前可能需要数据存储的完整快照。这可能发生在应用程序第一次启动时,或者在由于处理逻辑的更改而需要重新处理整个数据集的时候。Brooklin的可扩展连接器模型可以支持这样的场景。
事务支持
许多数据库都支持事务,对于这些数据源,Brooklin连接器可以确保事务边界得到维护。
更多的信息
有关Brooklin的更多信息,包括其架构和功能的概述,可以查看LinkedIn以前的工程博客文章。
在Brooklin的第一个版本中,详细介绍了Kafka镜像特性,可以使用LinkedIn提供的简单指令和脚本来测试它。同时LinkedIn也正在为项目添加对更多源和目标的支持
有什么问题也可以直接在 Gitter上联系LinkedIn!
接下来的计划
自2016年10月以来,Brooklin已经成功地运行了LinkedIn的工作负载。它已经取代了Databus,成为LinkedIn针对Espresso和Oracle数据源的变更捕获解决方案。并且也是是LinkedIn在Azure、AWS和LinkedIn之间移动数据的流媒体桥接解决方案,其中包括每天产生的许多Kafka集群中镜像数万亿条消息。
LinkedIn正在继续构建连接器,以支持其他数据源(MySQL、Cosmos DB、Azure SQL)和目的地(Azure Blob storage、Kinesis、Cosmos DB、Couchbase)。还计划向Brooklin添加优化,比如根据流量需求自动伸缩的能力,在镜像场景中跳过消息的解压缩和重新压缩以提高吞吐量的能力,以及额外的读写优化。
精彩推荐:
参考文章:https://engineering.linkedin.com/blog/2019/brooklin-open-source
部分文字、图片来自网络,如涉及侵权,请及时与我们联系,我们会在第一时间删除或处理侵权内容。负责人:曾菲 电话 0731-82568809


 400-607-0568
400-607-0568